= COMPLETED =
About[]
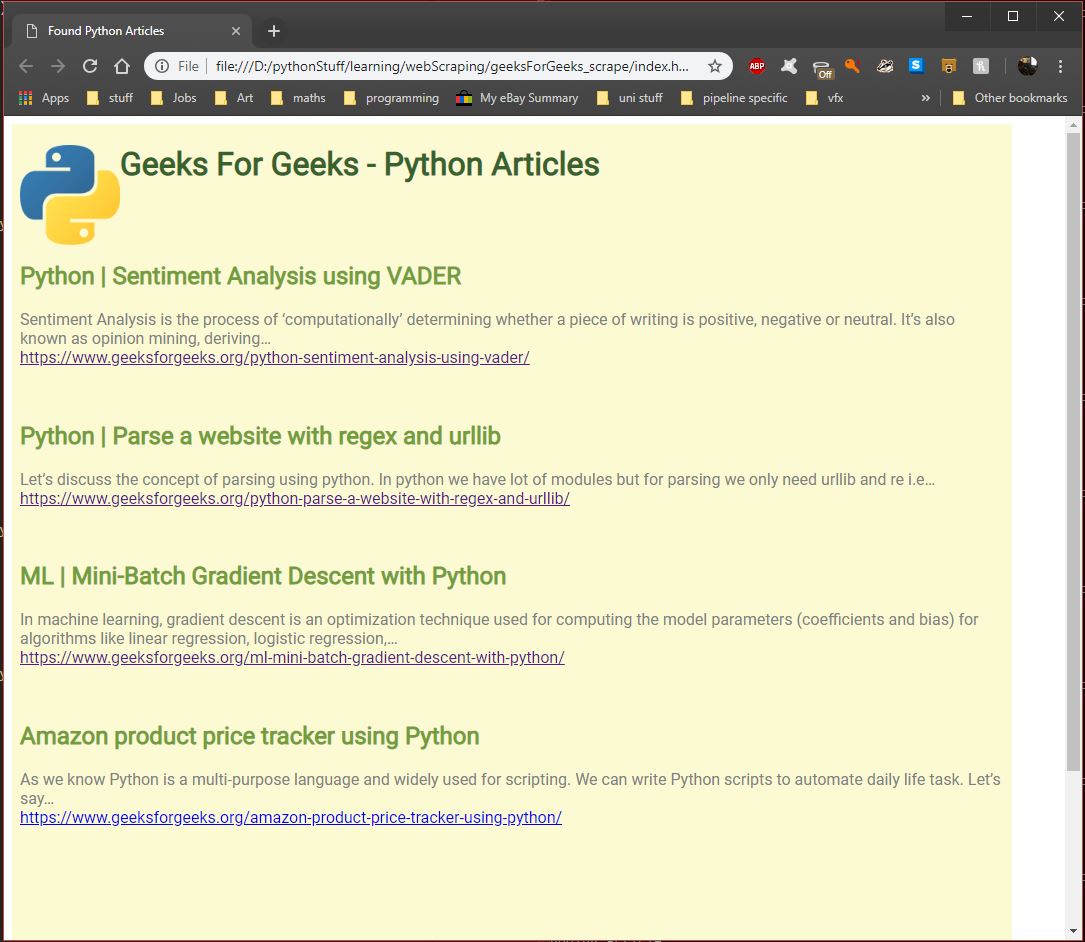
This script was intended to scrape some of my favourite programming sites and return the articles that spoke about the Python programming language. Displaying them neatly with a header of the article name, summary of what the article is about, and a link to the full article.
Git : Article-Scraper
What I learnt[]
For this project I needed to brush up on how to use BeautifulSoup, so I went to YouTube and found Python Tutorial: Web Scraping with BeautifulSoup and Requests which conveniently taught me the basics of using the Requests module as well as how to read and write information to .csv files using the csv module.
This tutorial taught me enough about how to use BS4 and Requests to allow me to start with my own project. I initially also set out to use csv to read and write my information to however I quickly decieded that I wanted a prettier way of displaying the information, a better way of linking to the full articles, and an easier way of jumping into the scraped information than having to open up Excel every time the scrape was complete.
Difficulties I Faced[]
I had to try and remember how to use html and css the way I wanted to. Even though the layout and styling is super basic, I still hadn't touched any web development in at least 6 months or more so I had forgotten most of what I needed to write to get the styling working even it's current basic form.

I also found it difficult at first to get the writing to a html doc from python to work as expected. To be honest this was more due to the fact that I wasn't noticing that I was still accidentally trying to write to a text file instead of a html, I had forgotten to change a certain line that was writing to the new html...
Another miner issue I ran into was finding the portions of the site that I was looking for using BS4. Even though I had watched the tutorial and read some posts about the library I still found myself making little mistakes on how to find certain portions, such as the link address for the articles. Then remembering to treat the found items as lists, for example to find the link in the headline I needed to do the following:
# Inside a loop that searched all of the article tags.
# Get the link from the header.
link = article.h2.find('a', href=True)
link = link['href']
Working out when I need to use the '.text' on the ends is something I still don't totally understand. For example:
header = article.h2.a.text